 [Blaxel](https://app.blaxel.ai/) is a computing platform where AI builders can **deploy AI agents easily**. This tutorial demonstrates how to deploy your first workload on Blaxel.
## Quickstart
Welcome there! 👋 Make sure you have created an account on Blaxel (here → [https://app.blaxel.ai](https://app.blaxel.ai)), and created a first [workspace](Security/Workspace-access-control). Retrieve the workspace ID.
[Blaxel](https://app.blaxel.ai/) is a computing platform where AI builders can **deploy AI agents easily**. This tutorial demonstrates how to deploy your first workload on Blaxel.
## Quickstart
Welcome there! 👋 Make sure you have created an account on Blaxel (here → [https://app.blaxel.ai](https://app.blaxel.ai)), and created a first [workspace](Security/Workspace-access-control). Retrieve the workspace ID.
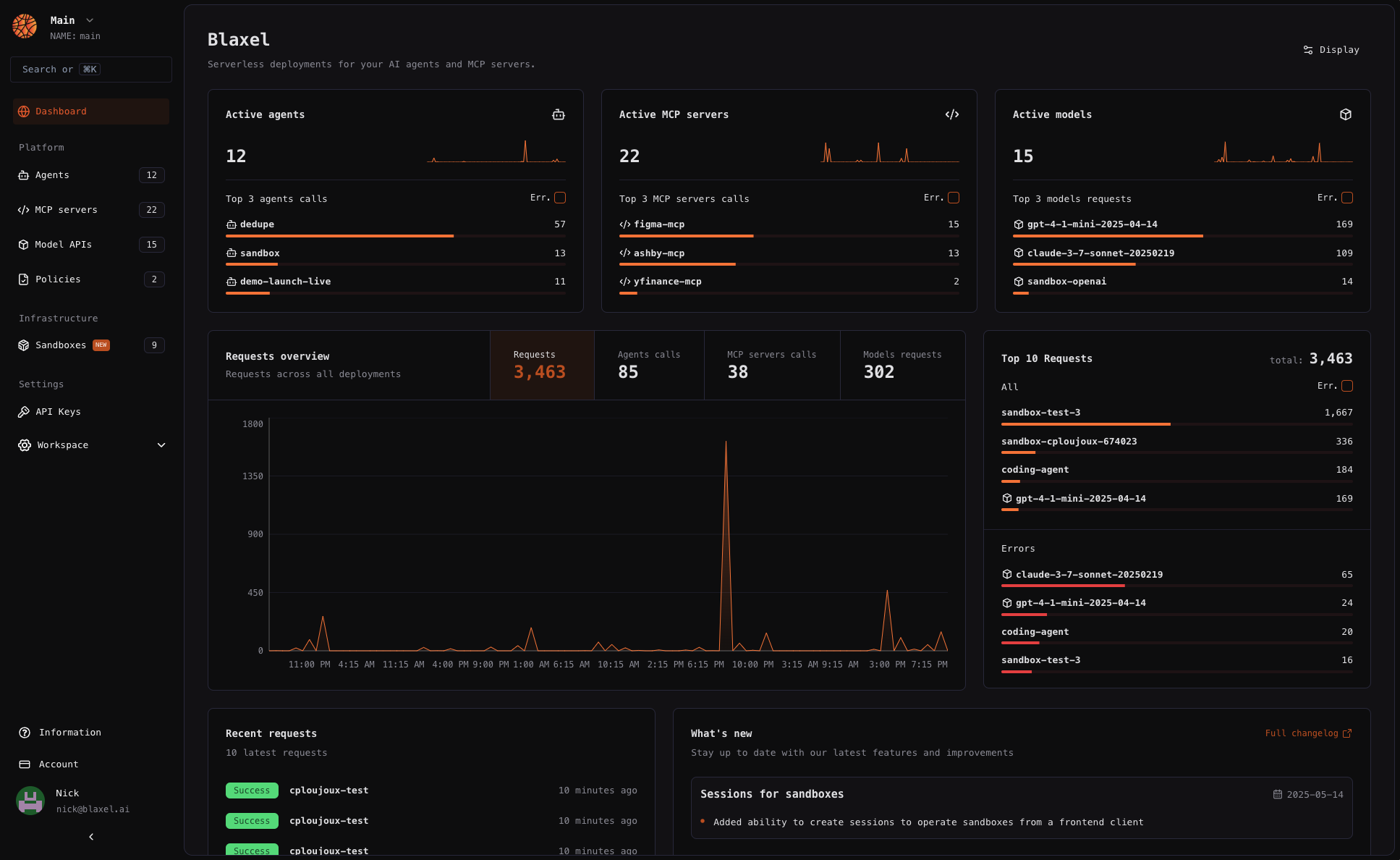 An *AI agent* is any application that leverages generative AI models to take autonomous actions in the real world—whether by interacting with humans or using APIs to read and write data.
An *AI agent* is any application that leverages generative AI models to take autonomous actions in the real world—whether by interacting with humans or using APIs to read and write data.
{loading ? (
) : (
);
}
// InfoCard component for consistent styling
function InfoCard({ title, children }: { title: string, children: React.ReactNode }) {
return (
Loading sandbox...
{/* Left side - Sandbox Information (1/3) */}
{previewUrl}
{/* Right side - Preview Iframe (2/3) */}
)}
Sandbox Information
{sessionInfo?.name || "N/A"}
{processes.length === 0 ? (
) : (
<>
{processes.map((process, idx) => (
))}
)}
No processes running
{process.name}
Command: {process.command}
PID: {process.pid}
{previewUrl ? (
) : (
)}
{previewUrl}
No preview available