Concepts
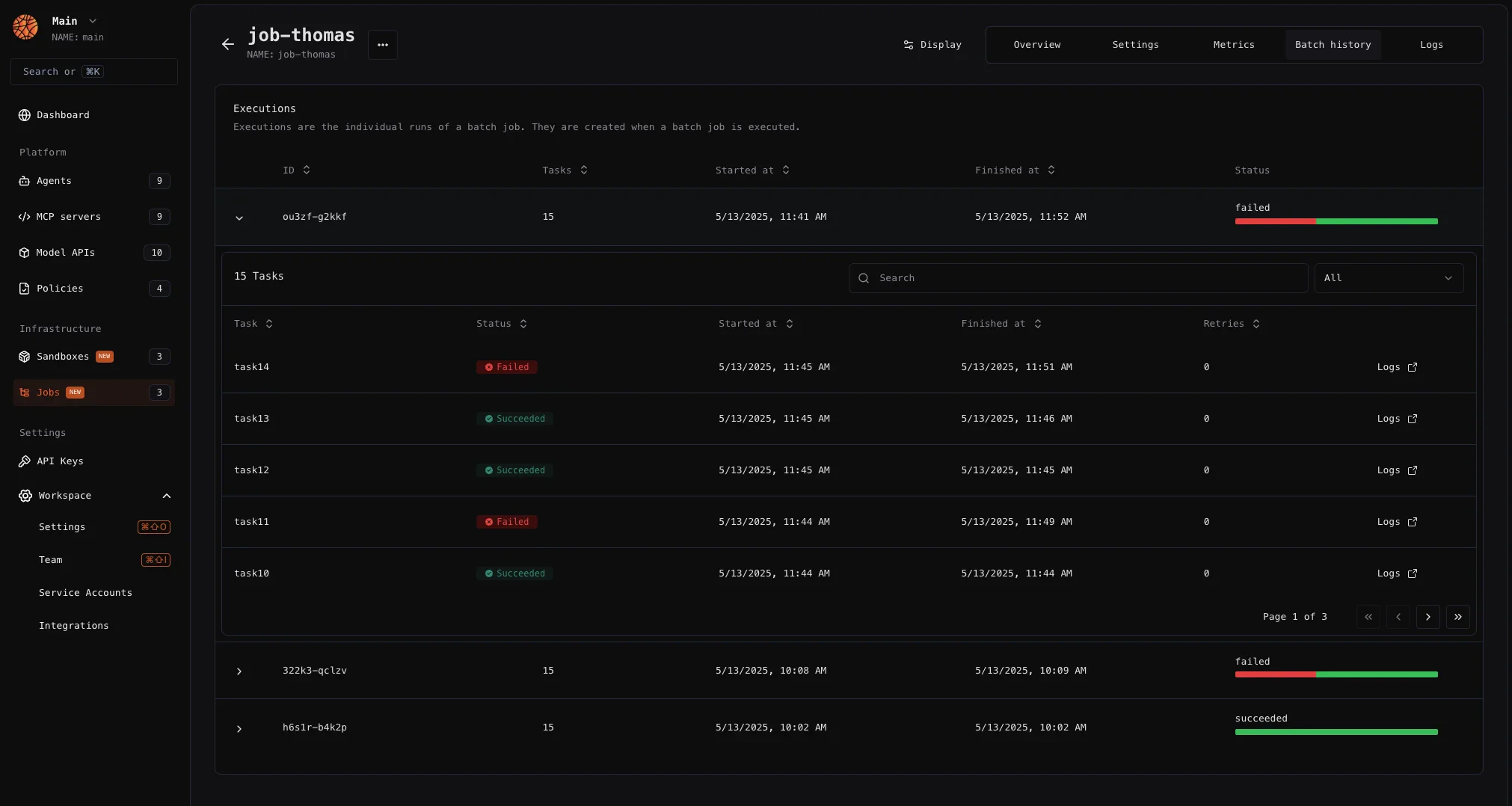
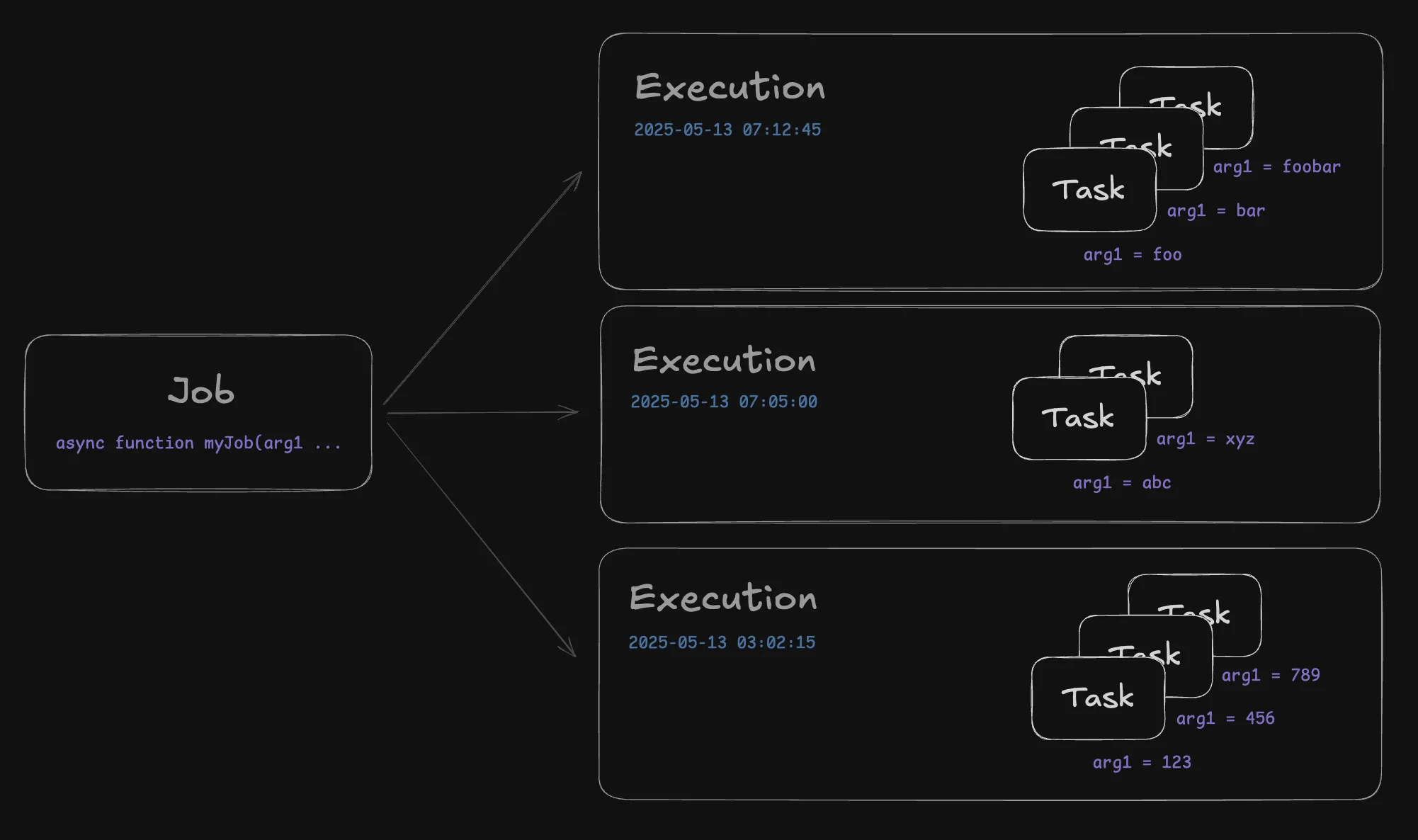
- Job: A code definition that specifies a batch processing task. Jobs can run multiple times within a single execution and accept optional input parameters.
- Execution: A specific instance of running a batch job at a given timestamp. Each execution consists of multiple tasks running in parallel.
- Task: A single instance of a job definition running as part of an execution.
Get started with Batch Jobs
Develop a job using Blaxel SDK
Read our guide for developing batch AI jobs leveraging Blaxel developer tools.
Deploy a job on Blaxel
Learn how to deploy your batch job on Blaxel as a serverless endpoint.
Manage environment variables
Learn how to manage secrets and environment variables for your batch job.