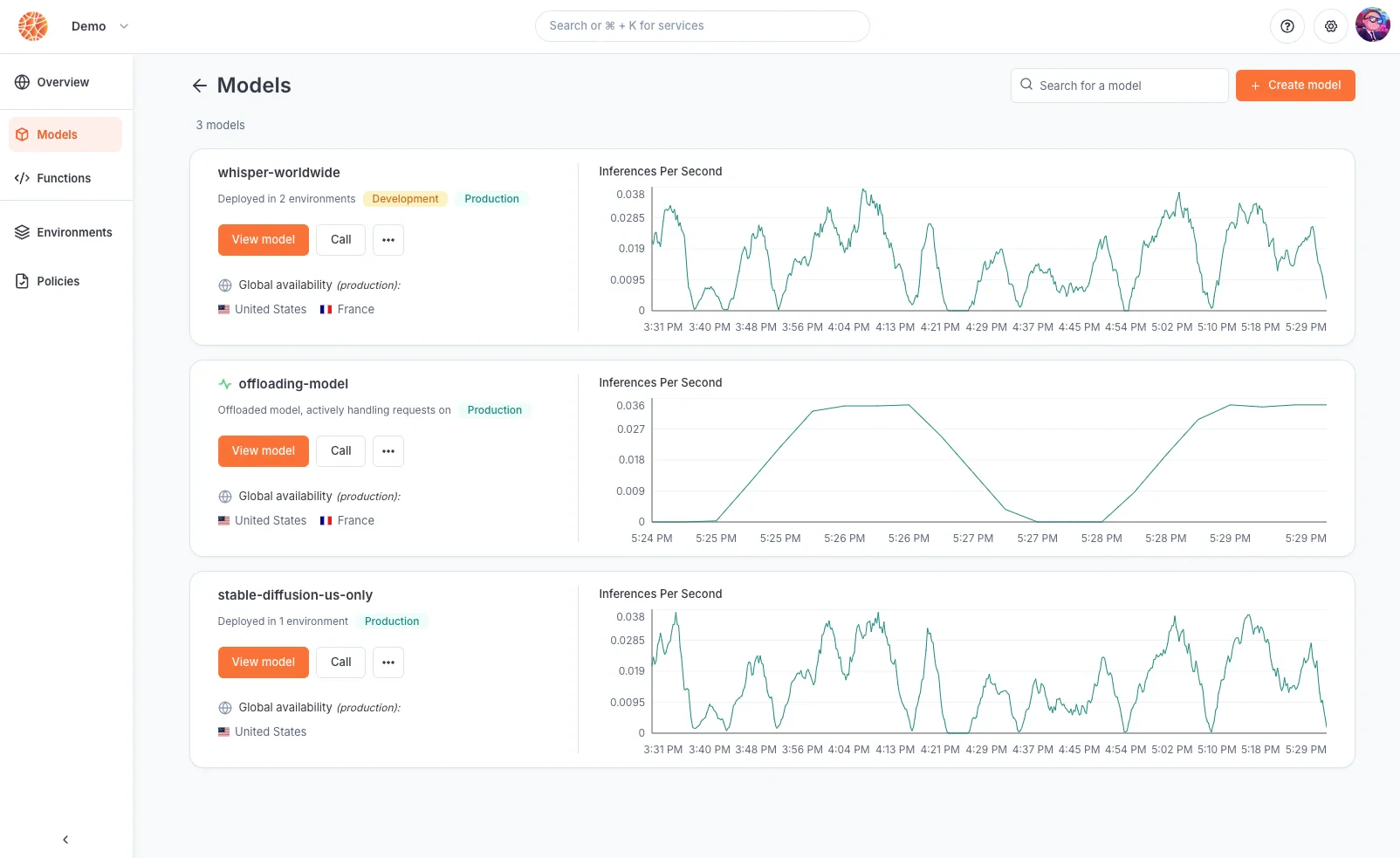
How model deployment works
Introduction
Blaxel is a cloud-native infrastructure platform that is natively serverless. Any AI workload pushed to Blaxel is run in response to requests without requiring provisioning or management of serving/inference servers or hardware. It automatically scales compute resources and you pay only for the compute time used. Blaxel is also natively distributed. By default, all workloads (such as an AI model processing inference requests for example) run across multiple execution locations, that can span over multiple geographic areas or cloud providers, in order to optimize for ultra-low-latency or other strategies. This is accomplished by decoupling this execution layer from a data layer made of a smart distributed network that federates all those execution locations.Models and deployments
Blaxel model deployment works using two conceptual entities: models and deployments.- Models are the base logical entity labeling an AI model throughout its life-cycle. A model can be instantiated into multiple deployments over different environments. This effectively lets you run multiple versions of the model at the same time, each on a different environment.
- Deployments (a.k.a model deployments) are the instantiation of one model version over one specific environment. For example, you can have a deployment XYZ of model ABC on the production environment.
- Executions (a.k.a inference executions) are ephemeral invocations of model deployments by a consumer. Because Blaxel is serverless, a model deployment is only materialized onto one of the execution locations when it actively receives and processes requests. Workload placement and request routing is fully managed by the Global Inference Network, as defined by your environment policies.
Deployment life-cycle
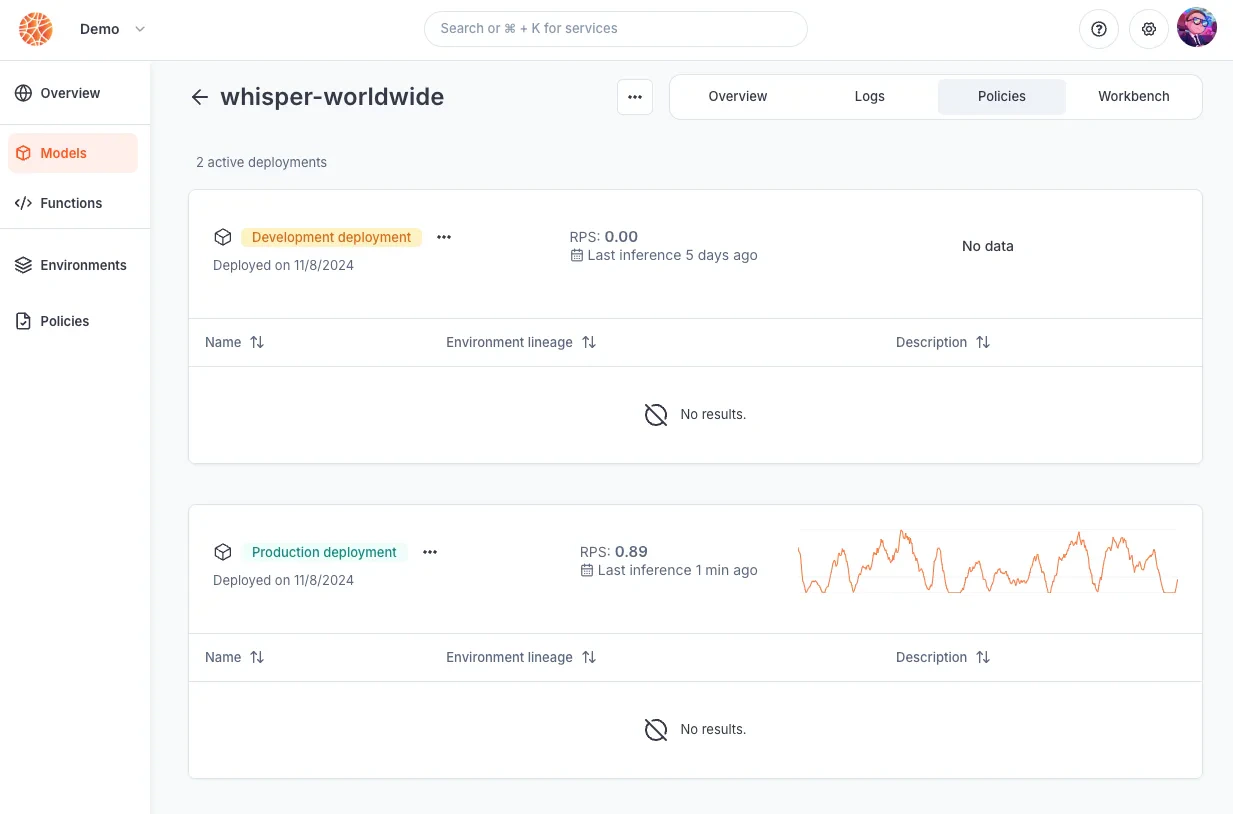
Deploying a model
Deploying a model will create the associated model deployment. At this time:- it is reachable through a specific endpoint
- it does not consume resources until it is actively being invoked and processing inferences
- its deployment/inference policies are governed by the associated environment
- its status can be monitored either on the console or using the CLI/APIs
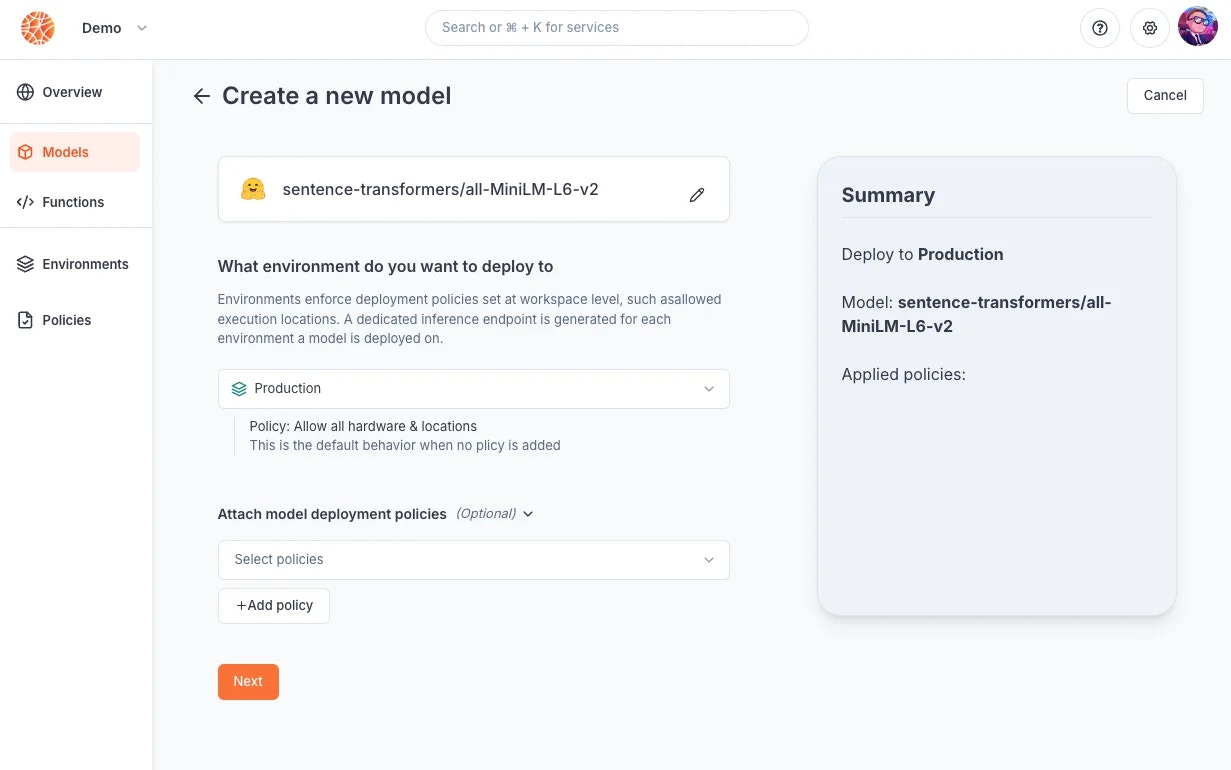
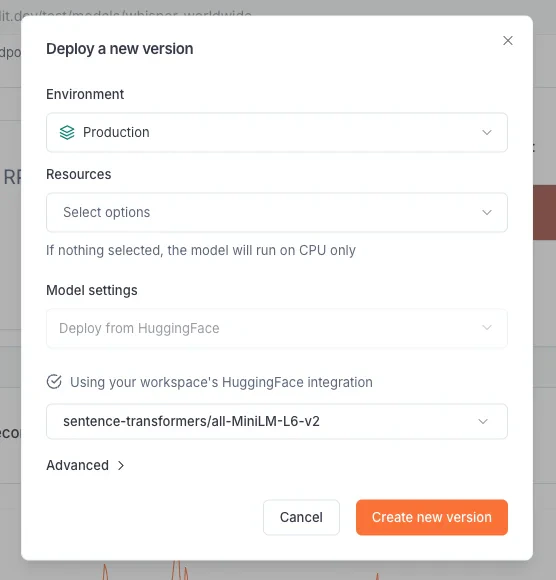
Updating a model version
As you iterate on software development, you will need to update the version of a model that is currently deployed and used by your consumers. One way to manage this is through multiple environments, and releasing the model version that is on one environment (e.g. development) to another environment (e.g. production). Another more straightforward way is to directly update a model deployment on an environment. When updating a model deployment, you can:- update the underlying model file/origin
- update the inference runtime for the model
- update the policies directly attached to the model deployment
Deactivating a model deployment
Any model deployment can be deactivated at any time. When deactivated, it will no longer be reachable through the inference endpoint and will stop consuming resources. Models can be deactivated and activated at any time from the Blaxel console, or via API or CLI.
Deployment reference
Model origins
Blaxel supports the following origins for models:- Uploading a file. Use a static file containing the model. Uploading through the interface has a limit of 5GB, else you must use the CLI.
- For the moment, Blaxel only supports uploading Torch-based models. We are currently working on extending model support, please reach out if you need a specific model type.
- Supported extensions:
.MARonly
- HuggingFace. Blaxel will use your workspace integration to retrieve any model deployed on HuggingFace. For private models, it will only be able to retrieve models within the scope of allowed models for your HuggingFace token.
Runtime
Blaxel suggests an optimized inference runtime for each model you attempt to deploy. You can override it by passing the Docker image for a custom inference runtime when deploying the model. Blaxel natively supports the following runtimes:- Blaxel Transformers/Diffusers: our optimized inference engine made for Transformers and Diffusers models
- Blaxel Torch: our optimized inference engine made for Torch-based models
- TGI
- TEI
Environment
You must choose an environment when deploying a model on Blaxel. Environments allow you to pre-attach policies to a model deployment (for example: to make it so the model only runs in certain countries, or on a certain hardware).Policies
Additional policies can be optionally attached to a model deployment directly. If there already are policies set in the environment, policies of the same policy type (e.g. location-based, flavor-based, etc.) will collide. In this case, the result will be as described here.Resources
Blaxel allows you to specify which flavors (i.e., which CPU types) should be used for running a particular model. Flavors refer to the specific CPU types that the model deployment will use for processing inferences. During inference execution, the Global Inference Network intelligently routes each request to a location containing the desired CPU types. It then schedules the workload based on resource availability, ensuring optimal performance.You can only select flavors allowed by the policies set in the environment or the deployment.
Deploy a replica of an on-prem model
Minimal-footprint deployments can be set up by referencing a model deployed on your own private infrastructure (on-prem or cloud) and making it overflow on Blaxel only in case of unexpected burst traffic or infrastructure failure.Deploy custom models from HuggingFace
Learn how to deploy public or private AI models from HuggingFace on Blaxel.